

Photo by Mario Heller on Unsplash
Microservices 101: Unpacking the Basics
Understanding what microservices really are and how they work.


Think back to just two years ago, when I was in high school, dreaming about becoming a developer. Back then, I thought all the cool code for websites was just sitting on people's devices – a funny assumption, looking back! 😅
As I learned more about web development, I discovered that websites are like puzzles with lots of different pieces. There's the part people see (the frontend), the behind-the-scenes stuff (the backend), databases for storing info, special codes that help different services talk to each other (APIs), and the place where everything lives online (hosting).
But my journey of discovery didn't stop there. Relatively recently, I stumbled upon the concept of microservices. In essence, microservices offer a methodology for constructing highly scalable, superfast, and resilient web applications.
As I keep exploring this world of making whole websites, I've decided to share this learning journey through a series of blogs. This article marks the inaugural installment of that series, where we'll begin by unraveling the fundamental basics of microservices.
So, without further ado, Let's get started🚀.
First things first, What is a microservice?
To get a clear picture, let's first take a quick look at how you might be building the backend of your applications right now.
If you're a full-stack developer, the method you're likely familiar with is the "monolithic" approach.

This is a common way to structure your backend. In simple terms, all the different parts of your application – like routing, middlewares, business logic, and database access – work together as a single entity and may be within a single server.
Now, let's dive into the definition of microservices. We can actually tweak the earlier description just a bit:
Microservices architecture is an approach where each component like routing, middlewares, business logic, and database access needed to run a SPECIFIC FEATURE (it can be one or sometimes more than one feature) of your application operates independently as a small service. Your entire application is broken down into these small building blocks, or say microservices. These services communicate with clients or each other through well-defined APIs to make the whole application function.
With the microservices approach, the backend of your application might look something like this...
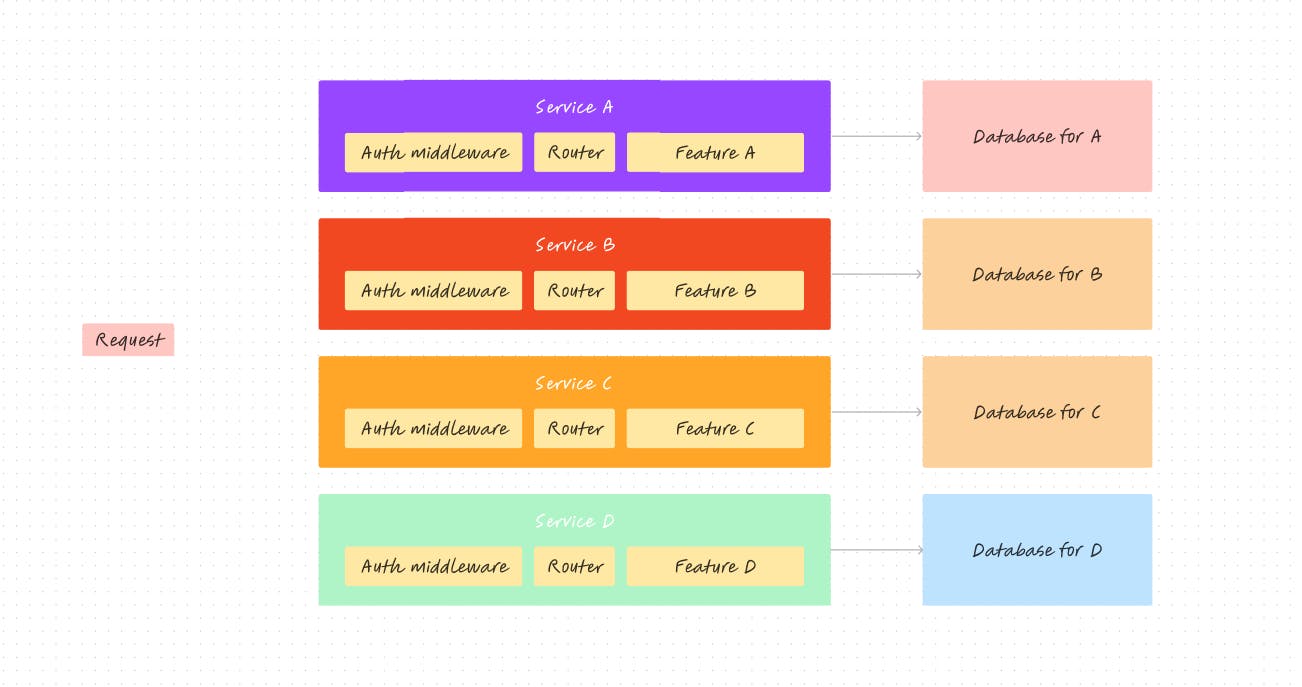
As you can see in the example above, each feature is deployed as a separate entity. So, even if one or two services encounter an issue and go down, the other services can still keep running. Of course, we wouldn't want any service to go down, but the point is that we're not in a total loss situation. This is one of the key reasons why microservices architecture is considered more reliable than the monolith approach.
Now, if we start thinking 🤔, this type of architecture offers more than just reliability. It brings along several other advantages too:
Flexibility: Since different features are implemented as separate microservices, they can be developed by different teams, at different paces, and using different tech stacks. This flexibility can be a real game-changer.
Scalability: Each service can be scaled independently as the demand for the corresponding feature increases. This makes it much simpler to scale up your entire application as needed.
It is also called fine-grained scalability.
DevOps and continuous delivery (CD): Microservices are a good fit for DevOps and continuous delivery (CD) practices. This is because microservices can be developed, tested, and deployed independently, which makes it easier to automate the software delivery process.
Management of data with microservices.
After understanding the concept of the microservices architectural approach for developing backends for applications, you might start to think that these are easy to develop and should have already been a standard approach for building backends in the industry. From a distance, it seems like there are only advantages to using this approach during development. However, let me clarify that this is not necessarily the case.
Developing microservices comes with its own set of challenges:
Cost: While microservices can provide cost savings in certain scenarios, they can also introduce additional infrastructure like a separate database for each service and operational costs for multiple services.
Initial Development Complexity: While microservices can provide benefits in the long run, the initial development of a microservices-based application can be more complex and time-consuming due to the need to design, develop, and coordinate multiple services.
Versioning and Compatibility: As microservices evolve independently, maintaining backward and forward compatibility can become difficult. Managing multiple versions of services and handling changes in APIs can be sometimes challenging if it is not thought of beforehand.
Data Consistency: Maintaining data consistency across multiple microservices can be complex. Since each microservice generally has its own database, ensuring that data remains consistent and up-to-date across the system can be a significant challenge.
Let's look at an example to understand these problems better. Consider you are running an e-commerce website where:
Users can sign up.
Users can have a look at the list of all the available products, and
Users can purchase a particular product.
Building this application with a monolith-style approach would be relatively straightforward.
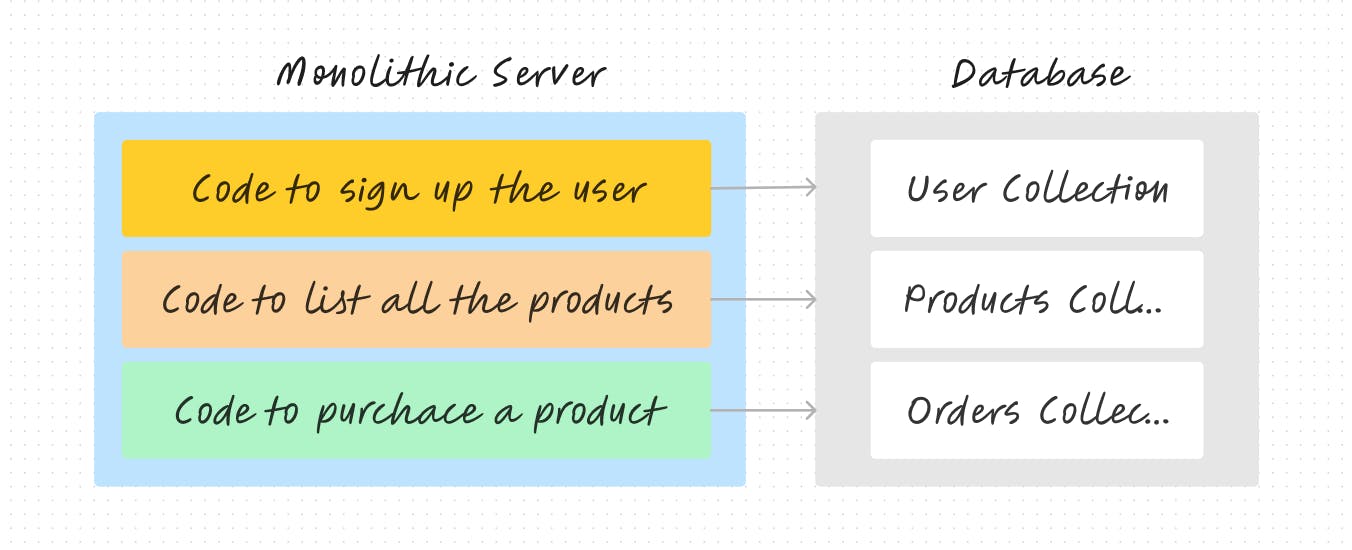
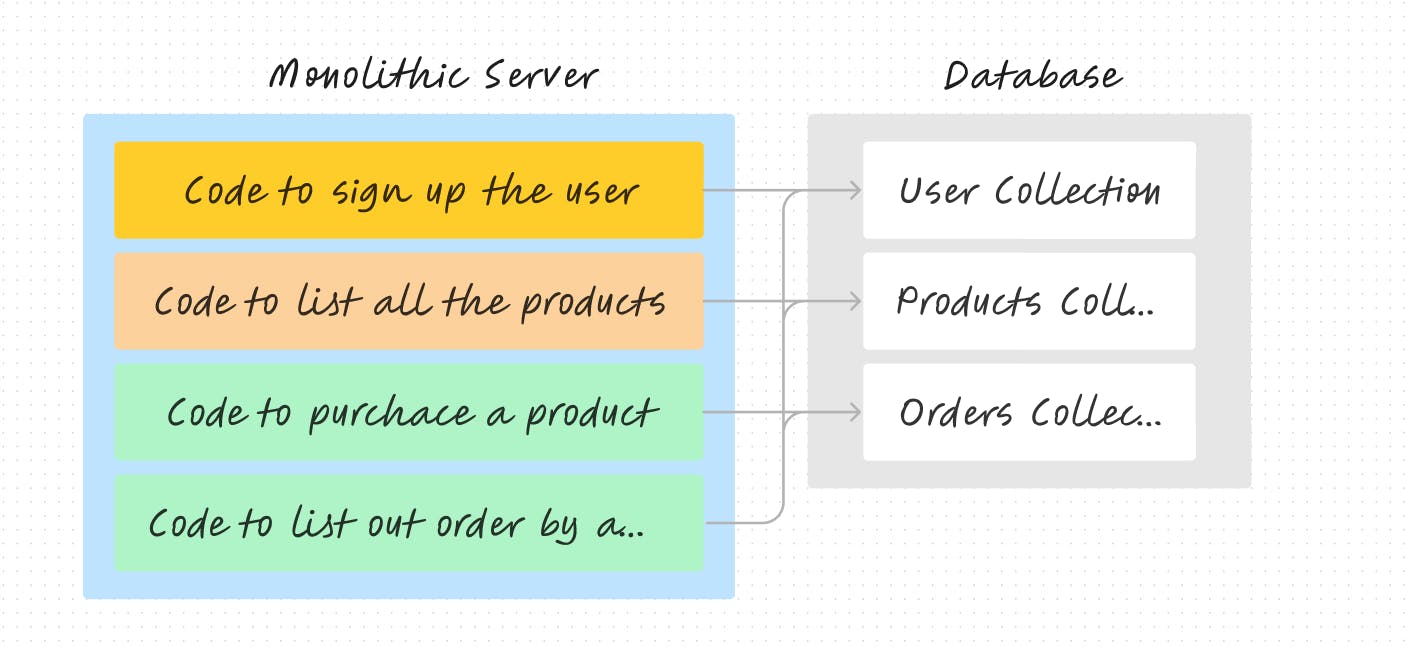
Now consider you want to add a extra functionality to list all the orders made by a particular user.
Adding this kind of feature would be straightforward with a monolith architecture. It would simply be a matter of adding extra code to the same server which accesses the database, checks all three collections, and returns all the orders per user.
This same application in a microservice would look something like this:

Now, the last three challenges of what I listed above are quite evident here, that is
Initial Development Complexity: In this example, we can see that adding a new feature is a challenge. Directly accessing the database of other services is out of the question because:
The database schema and its structure might change unexpectedly (remember it might be the case that different services are maintained by different teams).
Also, by letting 2 services access the same database, we are introducing dependency between two services. That is, if the database of any one service becomes unavailable, it would result in not one but two services going down with it.
So many more things to be taken care of while the initial development, isn't it?
Versioning and Compatibility: For the proper functioning of the application, the services need to communicate with each other. For example, Service C needs to communicate with Service A and Service B to access the record of users and products to implement the order functionality correctly. This might be a challenge as the services are developed independently. There might be a case where the new version of Service A's API is modified to accept the query parameters in a different format. In this case, we will need to properly modify Service C as well so that it can communicate with Service A correctly.
Data Consistency: There might be a case where the team managing Service B decides to change the IDs of all the products. Now, in the database (Order collection), the products are referenced by the IDs that no longer exist. This would be a really bad situation for any e-commerce platform💀. To avoid this condition, the data consistency between different microservices needs to be maintained, which is not that big of a deal in a monolith-style architecture.
All these challenges can be more or less tackled with a well-designed communication flow between services. And that's exactly what we'll delve into in the next section.
Communication between microservices.
When it comes to communication between microservices, two main strategies come into play: synchronous and asynchronous communication.
Synchronous Communication:
In synchronous communication, services interact directly through well-defined APIs, exchanging requests and responses.
To illustrate this with our e-commerce example, using synchronous communication would look like this:

While synchronous communication might seem simpler compared to asynchronous, it can introduce dependencies between services. The downside? The entire process is only as fast as the slowest request. Let's see how this plays out in our example:
Consider service D, which needs data from services A, B, and C to compute order details for a user. If service A responds in 10 seconds, service B in 10 seconds, but service C takes 30 seconds to respond, service D will need at least 30 seconds to generate its response. The chain is only as swift as its weakest link.
Asynchronous communication:
Another approach involves asynchronous communication. Here, services emit events when specific actions occur. These events are picked up by an event bus, a dedicated service that relays the events to interested parties.
In our example scenario, we have services A, B, C, and the newly introduced D. When a new user signs up, service A emits an event. The event bus catches this event and broadcasts this event to all services. Service D, which handles user purchases, listens to these events by event bus, and whenever a user registers, service D updates its database with a new entry, initializing it with zero orders. When an order is placed, service C emits an event, the event bus relays it, and service D updates the user's purchase history accordingly.
This can be visualized as follows:
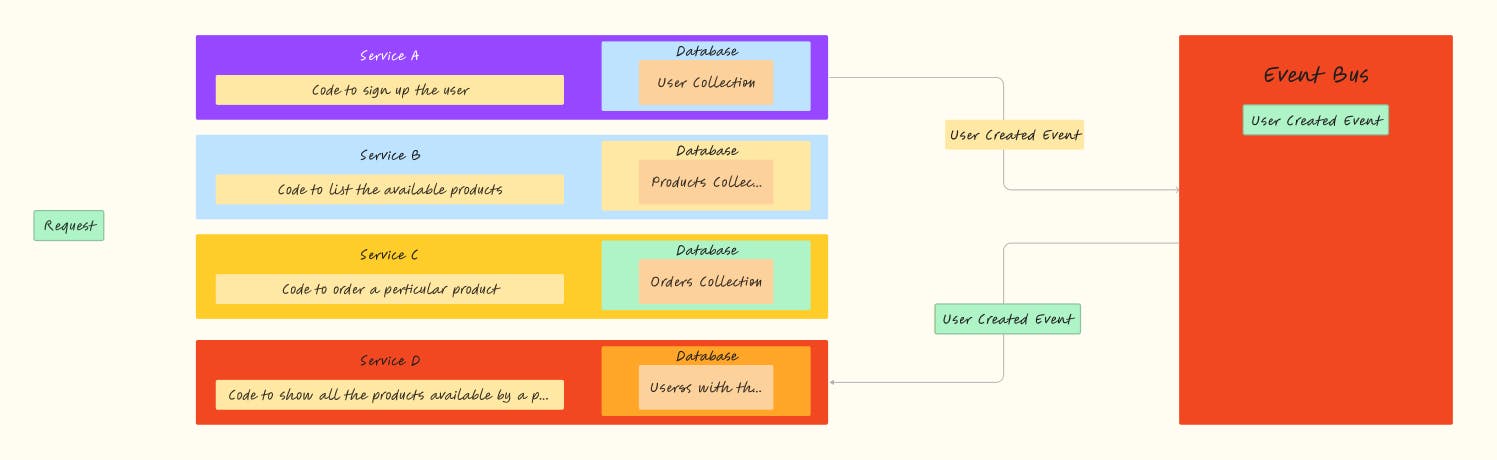
In this setup, services can be seen as truly independent. Even if services A, B, C, or the event bus experience downtime, service D can continue functioning autonomously. It maintains its own records and doesn't rely on other services for immediate data retrieval. This autonomy boosts the performance of service D while adding resilience to the system.
However, a drawback of this approach is data duplication. Multiple services are storing same data in two different databases. But the trade-off is increased application performance and greater failure resilience.
Wrapping Up: Final Thoughts
When it comes to software development, making choices often involves striking a balance between various factors. The decision to adopt microservices isn't a one-size-fits-all solution for every backend challenge. It's a choice that should be made thoughtfully, taking all relevant considerations into account.
And with that, we've reached the end of this blog. I hope you found the insights valuable and engaging.
In the next part, I'll take things a step further. I will dive into creating a mini-microservice application using event-driven communication with React and Express. This hands-on exercise will provide the readers with an even deeper understanding of how microservices work.
Until then, I hope you have a wonderful time! 🙋♂️